即可将网页分享至朋友圈
近日,信息与通信工程学院图像处理团队博士生李海鹏在图像处理/图形学/计算机视觉领域的顶级期刊IEEE Transactions on Image Processing (TIP),ACM Transactions on Graphics(TOG),International Journal of Computer Vision(IJCV)发表研究论文。TIP和TOG分别是图像处理领域和图形学领域排名第一的期刊,而IJCV是计算机视觉领域两大顶级期刊之一,三者都属于中国科学院一区/CCF A类期刊。
发表在TIP的论文Single-Image-Based Deep Learning for Segmentation of Early Esophageal Cancer Lesions(早期食道癌病灶分割的单图深度学习方法)以2022级博士生李海鹏和2020级硕士生刘丁瑞为共同第一作者,曾兵教授为通讯作者,合作单位包括生命科学与技术学院以及四川大学华西医院。
发表在TOG的论文DMHomo: Learning Homography with Diffusion Models(利用扩散模型学习单应性矩阵)以2022级博士生李海鹏为第一作者,刘帅成教授为通讯作者,合作单位包括四川大学、旷视科技和香港科技大学。同时,该论文受邀请将在今年7月于美国丹佛举行的SIGGRAPH-2024大会上做口头报告。
发表在IJCV的论文GyroFlow+: Gyroscope-Guided Unsupervised Deep Homography and Optical Flow Learning(陀螺仪引导的无监督单应性矩阵和光流估计)同样以2022 级博士生李海鹏为第一作者,刘帅成教授和曾兵教授为共同通讯作者,合作单位为旷视科技。
论文1:Single-Image-Based Deep Learning for Segmentation of Early Esophageal Cancer Lesions
(https://ieeexplore.ieee.org/document/10480373/)
准确的病灶分割对于早期食道癌(Early Esophageal Cancer - EEC)的诊断和治疗至关重要。然而直至今日,传统方法和基于深度学习的方法都未能满足临床需求,例如其平均Dice分数(医学影像分析中最重要的指标)很难超过0.75。为了解决这个问题,我们提出了一种新颖、独特的深度学习方法来分割EEC病变,它的整个训练和推理都仅仅依赖于患者的单幅病灶图像,因而构成一个“You-Only-Have-One”(YOHO)框架。这种“一图一网”的学习模式一方面完全保障了患者隐私,因为它不使用任何其他患者的信息作为训练数据;另一方面,它避免了几乎所有与泛化性相关的问题,因为每个训练好的网络仅应用于同一张输入图像,基于此我们可以尽可能地将训练推向“过拟合”,从而提高分割准确性。YOHO的技术细节包括与临床医生交互从而利用他们的专业知识,对单张病灶图像进行基于几何的数据增强以生成训练数据集,以及一个基于边缘增强的UNet网络。我们在临床中收集了一个新的EEC数据集,YOHO实现了平均0.888的Dice分数,与现有的深度学习方法相比有了显著的提高,朝着临床应用迈出了重要一步。
如图1所示,给定一张内窥镜图像x,该图像包含诸如早期食道癌(EEC)或息肉(Polyp)等病灶,YOHO由以下三个步骤构成:(1) 实施数据增强以生成多样化、高质量且单独针对x的训练数据集;(2) 基于这个数据集训练一个深度神经网络;(3) 将训练好的网络应用于病灶图像x上以完成病灶分割。
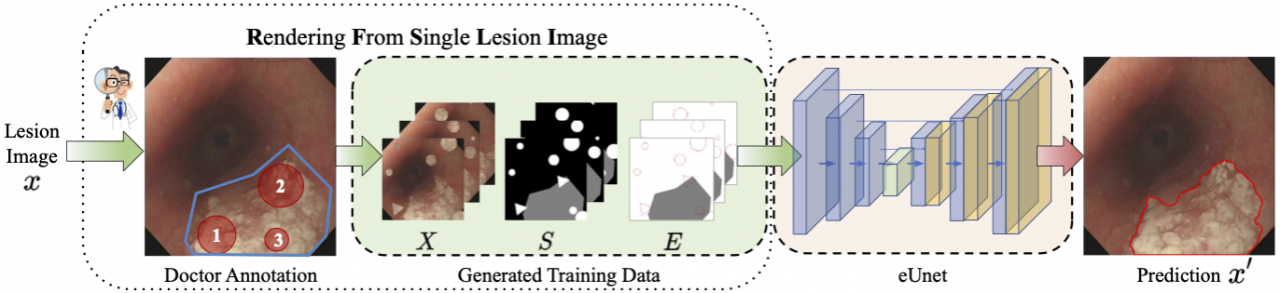
图1:在YOHO框架中,给定一张病灶图x,医生会围绕病灶区域勾勒一个多边形,用“蓝线”高亮显示,其中包括全部病灶组织和部分健康组织。接着,他们在多边形内部取几个圆形样本,用“红圈”并标上数字1、2和3来高亮显示。而后,YOHO 生成包含病灶图像(X)、分割掩码(S)和边缘标签(E)的训练数据集,并基于这个数据集来训练一个网络。最后,训练好的网络被应用于原始病灶图像x上,以产生分割结果x'。
YOHO以及对比方法在多个benchmarks(食道癌:EEC-2022;息肉:CVC-612 和Kvasir)上进行了实验,YOHO均取得了最佳效果,特别是早期食道癌病灶分割的效果大幅提升10个百分点以上。此外,我们和当下最流行的分割大模型 Segment Anything Model(SAM)也进行了公平对比,YOHO的客观/主观表现均更好。
论文2:DMHomo: Learning Homography with Diffusion Models
(https://dl.acm.org/doi/10.1145/3652207)
有监督的单应性估计方法面临着监督训练数据不足的挑战。为了解决这个问题,我们提出了DMHomo,一个基于扩散模型的有监督单应性学习框架。该框架生成具有准确标签、真实图像内容和真实帧间运动的图像对,确保它们满足高质量的图像配对要求。我们利用未标记的图像对和伪标签(如从现有方法计算得出的单应性矩阵和主平面掩码)来训练一个扩散模型,该模型能够生成一个有监督训练数据集。为了进一步提高性能,我们引入了一种新的概率掩码损失,它通过强监督训练识别异常区域,并采用迭代机制来连续优化生成模型和单应性估计模型。我们的实验结果表明,DMHomo有效地解决了有监督单应性矩阵学习中合格数据集的稀缺问题,并展现出了对真实世界场景的泛化能力。
如图2和图3所示,我们提出一个基于扩散模型的数据生成模块(DGM)来生成高质量的有监督数据集,此生成数据集可用来训练一个单应性矩阵模块(HEM)。当HEM收敛后,它可用来计算更加准确的伪标签,以用来完善DGM。最后,基于“预估-校正”理论,一个可以相互促进的循环就建立起来:更好的HEM能够进一步完善DGM;更完善的DGM能够进一步提升HEM的准确性。
DMHomo中的HEM在多个基准测试集上进行了对比实验,可以将之前的SOTA提升20%,并展现出强大泛化能力,特别的是,HEM是一种概率性估计运动的方法,降低了神经网络估计的不确定性问题;此外,DGM第一次实现了“运动到图像”的变换,它既能够被应用到现有的方法的数据增强中,还有潜力成为一个视频估计的框架。

图2:DMHomo整体框架的展示。DGM是基于扩散模型的数据生成模块,HEM是基于概率模型的单应性矩阵估计网络,此外,我们搭建一套基于“预估-校正”的循环框架来实现DGM和HEM的互促。
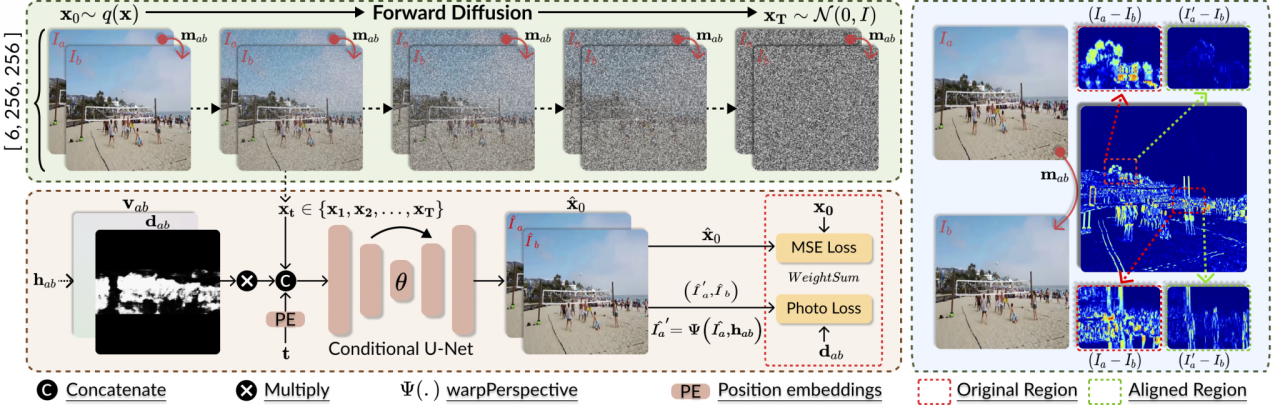
图3:DGM的示例图。在训练过程中,给定一对相邻帧和它对应的为标签条件,我们利用扩散模型来实现数据的生成,此间我们引入图像损失和重建损失。
论文3:GyroFlow+: Gyroscope-Guided Unsupervised Deep Homography and Optical Flow Learning
(https://link.springer.com/article/10.1007/s11263-023-01978-5)
现有的单应性矩阵和光流估计方法在诸如大雾、暴雨、夜晚和雪天等挑战场景中容易出错,因为诸如亮度和梯度恒定性等基本假设被打破。为了解决这个问题,我们提出了一种融合陀螺仪数据到单应性矩阵和光流学习的无监督方法。具体来说,我们首先将陀螺仪读数转换为名为陀螺场的运动场。其次,我们设计了一个自我引导的融合模块(SGF),用于融合从陀螺场中提取的背景运动,并引导网络关注运动细节。同时,我们提出了一个针对单应性矩阵的解码模块(HD),以结合陀螺场和SGF的中间结果来估计单应性矩阵。这是第一个融合陀螺仪数据和图像内容用于深度单应性和光流学习的深度学习框架。为了验证我们的方法,我们提出了一个新的数据集,涵盖了常规和具挑战性的场景。实验表明,我们的方法在常规和具挑战性的场景中均优于现有的最先进方法。
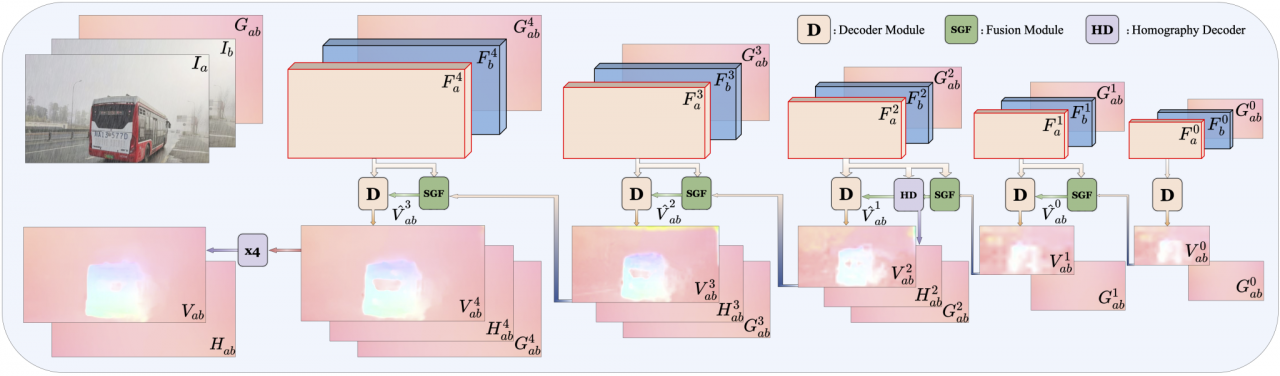
图4: 给定输入相邻帧Ia,Ib和帧间的陀螺域Gab,编码器会首先以金字塔形式提取不同尺度的图像特征信息,对应的陀螺域也会下采样到对应的尺度。解码器从金字塔的顶端出发,融合陀螺域和图像特征以估计光流和单应性矩阵,并按照“由粗到细”的形式,逐步上采样和优化编码器输出,以得到帧间的光流Vab和单应性矩阵Hab。
如图4所示,基于陀螺仪数据,我们的网络可以实现互促的单应性矩阵和光流估计:1. 在陀螺仪数据和光流的融合过程中,可以产生一个掩码用于区分前景和背景区域,此掩码可直接用到单应性矩阵估计中来祛除异常点;2. 一个更好的单应性矩阵可以用来替代陀螺仪数据,参与和光流的融合过程,提升光流估计的结果。
我们精心搜集了一个在各类挑战场景中拍摄得到的数据集,名为GHOF,包括四季白天和夜晚的街景,冬天的雪山和大雾天,夏天的暴雨,其中所有的数据都附带对应陀螺仪数据。最后汇总成为10,000个训练对和530个测试样例。对于测试样例,我们使用SOTA的标注工具,人工对每一对数据的单应性矩阵和光流进行标注。
在GHOF上,对比了单应性矩阵和光流估计中的经典方法、有监督方法、自监督方法和无监督方法,我们的GyroFlow+实现了SOTA表现。
编辑:刘瑶 / 审核:李果 / 发布:陈伟

